The following blog discusses a method to boost privately hosted Llama 2’s reasoning to outperform out-of-the-box LLMs to address challenges like Privacy and Control of Models, Boosting Reasoning Abilities, and Bilingual Support.
1. Overview
In recent years, the ability of Large Language Models (LLMs) to Reason, Adopt, and Act, has ushered in a new era of Cybersecurity Copilots. LLMs aspire to augment cybersecurity efforts by understanding threats and interacting with cyber tools, potentially bridging the cyber talent gap. However, realizing their full potential requires overcoming several hurdles.
First, out-of-the-box LLMs lack knowledge of organization-specific cybersecurity processes, policies, tools, and the IT infrastructure. This hinders its ability to make contextual decisions, leading to unreliable automation [1].
Second, there’s reluctance from enterprises and governments to adopt publicly hosted LLMs, driven by privacy, regulatory, and control concerns. A recent survey concluded that 75% of Enterprises don’t plan to use commercial LLMs in Production due to this reason [2].
Third, bilingual support specifically French for Canadian organizations.
Fourth, the need for cost-effective, versatile hosting solutions to support multiple cybersecurity team roles like Red Team, Blue Team, Threat Hunting, etc.
While privately hosted open-source models like Llama2 ensure ownership and privacy, they initially lack the sophisticated reasoning abilities of models like GPT 3.5/4. Llama2 (70B) reasoning was shown to be 81% worse than GPT4 in a recent benchmark [3].
This blog proposes a method to boost Llama2’s reasoning to outperform out-of-the-box LLMs for tailored cybersecurity tasks, using Penfield.AI. It details continuous fine-tuning techniques with Penfield’s curated data from Sr. Analysts (Section 3.3), applies Penfield’s curated data from prior tasks for enhancing model calls (Section 3.4), and uses Penfield’s Process Prompt for clear process instructions (Section 3.6). It also covers a hosting architecture enabling customized features like bilingual support (Section 4).
2. Limitations of generic LLMs in client-specific Cybersecurity applications
Key limitations of generic LLMs to drive client-specific Security copilots have been stated below.
2.1 Making Organization-specific Contextual Decisions
Out-of-the-box LLMs like GPT-4, trained on extensive data including documents, images, and videos, excel in text prediction but often fall short in tasks specific to organizations. They may generate generic, inaccurate, or even harmful content without tailored data or instructions relevant to a specific domain [5].
Without training on domain and client-specific data, models risk generating inaccurate or irrelevant text, known as hallucination [6]. This is exemplified in the decoding process of language models, where they convert input to output, often using beam search to estimate the most likely word sequences. This process, as shown in Figure 1, selects the most suitable sequences based on training data, highlighting the importance of domain-relevant training.
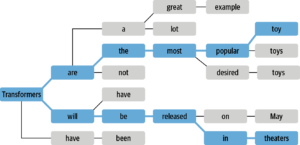
Figure 1. Beam Search [6].
For tasks such as developing anti-phishing code for a particular bank, Language Models (LLMs) might be ineffective without deep knowledge of the bank’s specific operations and systems, as shown in Figure 2.
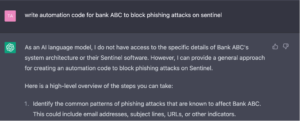
Figure 2. ChatGPT attempting to author automation code for a client-specific task.
The challenge is further aggravated in cybersecurity due to context-sensitive processes. Process gaps have already hindered the initial goal of SOAR (Security Orchestration, Automation, and Response) solutions to automate everything using off-the-shelf playbooks. For instance, a bank might react differently to the same cyber-attack on different servers, like online banking versus rewards, due to differences in technology, policy, and business importance [1].

Figure 3. The dependency of SOAR tools on defined processes [1]
This general challenge is further echoed by recent research that highlights while LLMs exhibit human reasoning, they falter with complex tasks. Karthik et. al. notes that current LLM benchmarks prioritize simple reasoning, neglecting more intricate problems [7].
This paper explores strategies to enhance LLMs with domain-specific data and instructions, enabling them to perform human-like tasks and detailed reasoning [8]. It also discusses how integrating Penfield.AI’s AI-generated documentation and process knowledge from senior analysts can facilitate complex reasoning in LLMs.
2.2 Privacy and Control
Recent data shows that over three-quarters of enterprises are hesitant to implement commercial Large Language Models (LLMs) like GPT-4 in product due to data privacy concerns [9]. This reluctance is mainly due to the need to share sensitive information, like IP addresses and security vulnerabilities, via internet-based APIs, conflicting with many firms’ privacy needs. This paper explores how privately hosted, open-source LLMs could mitigate these risks.
2.3 Bilingual Support
Bilingual support is crucial for organizations dealing with multi-language data. Open-source models like Llama2-chat are often English-centric and lack inherent multilingual abilities [10]. Multilingual transformers fill this gap by training on texts in over a hundred languages, enabling understanding of multiple languages without extra fine-tuning, known as zero-shot cross-lingual transfer [6]. Despite their primary language focus, models like Llama2 can be fine-tuned for multilingual support, which we will examine in this paper.
2.4 Cost-effective and Modular Deployment
High costs hinder the broad adoption of Large Language Models (LLMs) by enterprises. Developing and training such models demands substantial GPU investment, with examples like OpenAI’s GPT-3 needing over $5 million in GPUs. Operational costs, including cloud services and API usage, add to this financial strain [11]. Additionally, fine-tuning open-source models can be costly due to the high compute, storage, and hosting expenses, especially when full retraining is required for various applications and teams within an organization [8], as depicted in Figure 4.
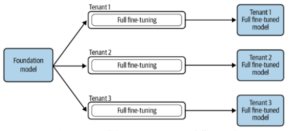
Figure 4. Full Finetuning of a Foundation Model across different tenants [8]
The paper will address how Perimeter-efficient Fine-tuning (PEFT) offers techniques to fine-tune models with fewer resources, focusing on using human context data from Penfield.AI. This approach is also relevant when managing multilingual capabilities [6], as maintaining multiple monolingual models substantially raises costs and complexity for engineering teams.
3. Building Tailored and Performant Security Copilots
Enjoying the blog? Download the full whitepaper here: Link
References
- Shabab, T. (2023). “Continuously Improving the Capability of Human Defenders with AI”. Penfield.AI. Available at: https://youtu.be/sRm4uWS7kkg [Feb 16, 2023].
- Business Wire. (2023). “Survey: More than 75% of Enterprises Don’t Plan to Use Commercial LLMs in Production Citing Data Privacy as Primary Concern”. Available at: https://www.businesswire.com/news/home/20230823249705/en/Survey-More-than-75-of-Enterprises-Don%E2%80%99t-Plan-to-Use-Commercial-LLMs-in-Production-Citing-Data-Privacy-as-Primary-Concern [Aug 23, 2023].
- Xiao Liu et. al. (2023). “AgentBench: Evaluating LLMs as Agents”. Available at: https://arxiv.org/pdf/2308.03688.pdf [Oct 25, 2023].
- Jie Huang et. al. (2023). “Towards Reasoning in Large Language Models: A Survey”. [May 26, 2023]
- OpenAI. (2022). “Aligning LLMs to follow instructions”. Available at: https://openai.com/research/instruction-following [Jan 27, 2022].
- Lewis et. al. (2023). “Natural Language Processing with Transformers”. Oreilly.
- Karthik et. al. (2023). “PlanBench Paper”. Journal/Conference. Available at: https://arxiv.org/pdf/2206.10498.pdf
- Chris Fregly et. al. (2023). “Generative AI on AWS”. Oreilly.
- Business Wire. (2023). “Survey: More than 75% of Enterprises Don’t Plan to Use Commercial LLMs in Production Citing Data Privacy as Primary Concern”. Available at: https://www.businesswire.com/news/home/20230823249705/en/Survey-More-than-75-of-Enterprises-Don%E2%80%99t-Plan-to-Use-Commercial-LLMs-in-Production-Citing-Data-Privacy-as-Primary-Concern.
- Meta Research. (2023). “Llama 2 Paper”. Available at: https://arxiv.org/pdf/2307.09288.pdf
- Smith, C. (2023). “What Large Models Cost You – There Is No Free AI Lunch”. Forbes. Available at: https://www.forbes.com/sites/craigsmith/2023/09/08/what-large-models-cost-you–there-is-no-free-ai-lunch/?sh=6b26181c4af7
- Xiao Liu et. al. (2023). “AgentBench: Evaluating LLMs as Agents”. Available at: https://arxiv.org/pdf/2308.03688.pdf [Oct 25, 2023].




